Table of Contents
HTSQL was created in 2005 to provide an XPath-like HTTP interface to PostgreSQL for client-side XSLT screens and reports. HTSQL found its audience when analysts and researchers bypassed the user interface and started to use URLs directly. The language has evolved since then.
HTSQL is a comprehensive navigational query language for relational databases and web service gateway.
https://demo.htsql.org/school
On the left is a URL, on the right is what a browser would show.
HTSQL is a query language for the web. Queries are URLs that can be directly typed into a browser; the output could be returned in a variety of formats including HTML, CSV, JSON, etc. HTSQL can be used as the basis for dashboarding tools and other browser-based applications. In this way, database queries can be shared, tweaked, and used in any number of ways.
SELECT "school"."code",
"school"."name",
"school"."campus"
FROM "ad"."school"
ORDER BY 1 ASC
On the left is an HTSQL query, on the right is SQL it is translated to.
HTSQL wraps your existing existing relational database, transparently handling SQL complexities for you. The current version of HTSQL supports SQLite, PostgreSQL, MySQL, Oracle, and Microsoft SQL Server. We’ve taken care to abstract differences between these SQL dialects so that a given HTSQL query has consistent semantics across database server implementations.
SELECT "school"."name", COALESCE("program"."count", 0), COALESCE("department"."count", 0)
FROM "ad"."school"
LEFT OUTER JOIN (SELECT COUNT(TRUE) AS "count", "program"."school_code" FROM "ad"."program" GROUP BY 2) AS "program" ON ("school"."code" = "program"."school_code")
LEFT OUTER JOIN (SELECT COUNT(TRUE) AS "count", "department"."school_code" FROM "ad"."department" GROUP BY 2) AS "department" ON ("school"."code" = "department"."school_code")
ORDER BY "school"."code" ASC
On the left is an HTSQL query, on the right is SQL it is translated to.
Besides typical expression algebra and function set, HTSQL provides sophisicated navigational query mechanism, composable query fragments and an extensive macro inclusion system. In particular, nested aggregations and projections are easy to understand and use.
Show me schools, and, for each school,
- its name, its location,
- number of programs and departments,
- and the average number of courses
across each of its departments?
On the left is a business inquiry, on the right is the HTSQL translation.
HTSQL is first and formost designed for the accidental programmer and as such provides a direct mapping of common business inquiries onto a computer parsable and executable syntax. Just because a query must be processable by a machine, doesn’t mean it shouldn’t be human readable.
from htsql import HTSQL
demo = HTSQL("pgsql:///htsql_demo")
rows = demo.produce("/school")
for row in rows:
print row
school(code=u'art',
name=u'School of Art & Design',
campus=u'old')
school(code=u'bus',
name=u'School of Business',
campus=u'south')
...
HTSQL can be embedded into any Python application to provide an intuitive object based query engine for complex reporting. It works out of the box with Jinja and other tools. We provide meta-data adapters for Django and SQLAlchemy.
We develop HTSQL to liberate the Accidental Programmer—professionals and data experts who are not software engineers by trade, but who must write database queries or data processing code to get things done. HTSQL handles routine data processing needs in an accessible, transparent, rigorous and embeddable manner.
We want HTSQL to be broadly usable. Our query language should provide business analysts, information scientists, and data curators self-service access and control over their database. Not only should these accidental programmers be able able to answer complex business inquiries themselves, they should be able to share the queries they create with their colleagues. HTSQL must be a productive tool for problem solving with a small learning curve.
We think aesthetics matter. When a data analyst is focusing on a domain specific problem, the HTSQL query language should do the heavy lifting but otherwise stay in the background. Translation of a business inquiry into the HTSQL query language must be natural and obvious. Initial query authoring is just the beginning. A database query is often the only human readable expression of a business rule, so each and every query must be a pleasure to review, share and maintain.
We know correctness is critical. The HTSQL query language is based upon a navigational data linking and flow processing model having consistent semantics that are independent of the underlying database architecture. The language designed to be composable so that query fragments can be independently tested and combined. HTSQL’s syntax is regular enough that syntax highlighting and context sensitive name lookup is possible.
We realize a query language is not a product. Instead, HTSQL is a tool used as part of a workflow solution or embedded into an application. Our public application program interface is be simple and stable. Further, since accidental programmers might require features which other software developers could build, we have an extensive plug-in interface for those who wish to add features to HTSQL itself. Between web service wrappers or plug-ins, it should be possible to customize almost every aspect of HTSQL without requiring a code fork.
HTSQL was designed from the ground up as a self-serve reporting tool for data analysts. With HTSQL, the easy stuff is truly easy; and, the complex stuff is easy too.
In this section we introduce the fundamentals of HTSQL syntax and semantics. For a more incremental approach, please read the HTSQL Tutorial. For the purposes of this section, we use a fictitious university schema.
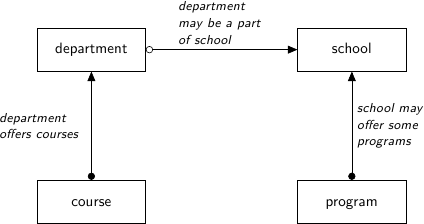
This data model has two top-level tables, school and department, where department has an optional link to school. Subordinate tables, course and program, have mandatory links to their parents.
Literal values:
| 3.14159 | ‘Hello World!’ |
|---|---|
| 3.14159 | Hello World! |
Algebraic expressions:
Predicate expressions:
| true |
Sieve operator produces records satisfying the specified condition:
| code | name | campus |
|---|---|---|
| bus | School of Business | south |
| mus | School of Music & Dance | south |
Sorting operator reorders records:
| code | name | campus |
|---|---|---|
| ph | Public Honorariums | |
| sc | School of Continuing Studies | |
| eng | School of Engineering | north |
| art | School of Art & Design | old |
Truncating operator takes a slice from the record sequence:
| code | name | campus |
|---|---|---|
| art | School of Art & Design | old |
| bus | School of Business | south |
Selection specifies output columns:
| name | campus |
|---|---|
| School of Art & Design | old |
| School of Business | south |
| College of Education | old |
| School of Engineering | north |
Title decorator defines the title of an output column:
| name | # of Dept |
|---|---|
| School of Art & Design | 1 |
| School of Business | 3 |
| College of Education | 2 |
| School of Engineering | 4 |
Output records could nest:
| name | school | |
|---|---|---|
| name | campus | |
| Accounting | School of Business | south |
| Art History | School of Arts and Humanities | old |
| Astronomy | School of Natural Sciences | old |
| Bioengineering | School of Engineering | north |
Calculated attributes factor out repeating expressions:
| code | num_dept |
|---|---|
| eng | 4 |
| la | 6 |
| mus | 4 |
| ns | 4 |
References carry over values across nested scopes:
| title | credits |
|---|---|
| Financial Accounting | 5 |
| Audit | 5 |
| Accounting Internship | 6 |
| History of Art Criticism I | 4 |
Locator operator picks a single record by ID:
| code | name | school_code |
|---|---|---|
| comp | Computer Science | eng |
A composite ID consists of labels separated by a period:
| department_code | no | title | credits | description |
|---|---|---|---|---|
| comp | 515 | Software Design | 3 | Study of good software development techniques: UML, object-oriented design, design patterns, GUI design principles, testing, debugging and profiling. |
Function id() returns the record ID:
| comp.102 |
| comp.130 |
| comp.150 |
The segment (/) operator embeds a result of a correlated query as a nested list. For instance, a list of schools could include associated departments:
| code | name | campus | department | ||
|---|---|---|---|---|---|
| code | name | school_code | |||
| art | School of Art & Design | old | stdart | Studio Art | art |
| bus | School of Business | south | acc | Accounting | bus |
| econ | Economics | bus | |||
| mm | Management & Marketing | bus | |||
| edu | College of Education | old | edpol | Educational Policy | edu |
| tched | Teacher Education | edu | |||
Nesting can be arbitrarily deep:
| name | department | |
|---|---|---|
| name | course | |
| title | ||
| College of Education | Educational Policy | Introduction to Education |
| Contemporary Society | ||
| Sociology of Childhood | ||
| Technology in the Classroom | ||
| Technology, Society and Schools | ||
| Economics and Education Policy | ||
| Politics and Education Policy | ||
| Education Policy Analysis | ||
| Children’s Literature | ||
| Education Policy and Practice | ||
| Social Analysis of Education Policy | ||
| Classroom Visit | ||
| Organizational Analysis of Education Policy | ||
| Seminar in Education Policy I | ||
| Seminar in Education Policy II | ||
| Qualitative Research in Education Policy | ||
| Teacher Education | Teaching Methodology | |
| Theory and Practice of Early Childhood Education | ||
| Methods of Early Science Education | ||
| Play as Education Method | ||
| Developmental Psychology | ||
| Selection of Learning Resources | ||
| Teacher Identity | ||
| Problems in Education Management | ||
| Challenges of Teaching the Gifted and Talented | ||
| Techniques of Mathematics Teaching | ||
| Techniques of Science Teaching | ||
| Techniques of Language Teaching | ||
| Problems in Education | ||
| Public School Internship | ||
| Preschool Internship | ||
| Special Topics in Teacher Education | ||
| Practice of Mathematics Teaching | ||
| Practice of Science Teaching | ||
| Practice of Language Teaching | ||
A query may have adjacent nested segments:
| name | department | program |
|---|---|---|
| name | title | |
| School of Art & Design | Studio Art | Post Baccalaureate in Art History |
| Bachelor of Arts in Art History | ||
| Bachelor of Arts in Studio Art | ||
| School of Business | Accounting | Master of Arts in Economics |
| Economics | Graduate Certificate in Accounting | |
| Management & Marketing | Certificate in Business Administration | |
| B.S. in Accounting | ||
| Bachelor of Business Administration | ||
| Bachelor of Arts in Economics | ||
Aggregates convert plural expressions to singular values.
Scalar aggregates:
Nested aggregates:
| 2.66666666667 |
Various aggregation operations:
| name | count(course) | max(course.credits) | sum(course.credits) | avg(course.credits) |
|---|---|---|---|---|
| Accounting | 12 | 6 | 42 | 3.5 |
| Art History | 20 | 6 | 70 | 3.5 |
| Astronomy | 22 | 5 | 66 | 3.0 |
| Bioengineering | 17 | 8 | 55 | 3.23529411765 |
Projection (^) returns distinct values. This example returns distinct campus values from the school table:
| campus |
|---|
| north |
| old |
| south |
In the scope of the projection, school refers to all records from school table having the same value of campus attribute:
| campus | count(school) | school | ||
|---|---|---|---|---|
| code | name | campus | ||
| north | 1 | eng | School of Engineering | north |
| old | 4 | art | School of Art & Design | old |
| edu | College of Education | old | ||
| la | School of Arts and Humanities | old | ||
| ns | School of Natural Sciences | old | ||
Projections combine with other language features in a natural way. The next example displays distinct program degrees offered by each school:
| name | count(program^degree) | program^degree |
|---|---|---|
| degree | ||
| School of Art & Design | 2 | ba |
| pb | ||
| School of Business | 4 | ba |
| bs | ||
| ct | ||
| ma | ||
Links between tables are automatic and relative, inferred from foreign key constraints. Unlink (@) permits arbitrary, non-relative linking.
| name | count(department) |
|---|---|
| School of Business | 3 |
| School of Engineering | 4 |
| School of Arts and Humanities | 6 |
| School of Music & Dance | 4 |
The query above returns schools with the number of departments above average among all schools.
HTSQL can output the result in a variery of formats. JSON:
{
"school": [
{
"code": "art",
"name": "School of Art & Design"
},
{
"code": "bus",
"name": "School of Business"
},
…
XML:
<?xml version="1.0" encoding="UTF-8" ?>
<htsql:result xmlns:htsql="http://htsql.org/2010/xml">
<school>
<code>art</code>
<name>School of Art & Design</name>
</school>
<school>
<code>bus</code>
<name>School of Business</name>
</school>
…
CSV:
code,name
art,School of Art & Design
bus,School of Business
…
Relational algebra is frequently inadequate for encoding business inquiries — elementary set operations do not correspond to meaningful data transformations. The SQL language itself is tedious, verbose, and provides poor means of abstraction. Yet, the relational database is an excellent tool for data modeling, storage and retrieval.
HTSQL reimagines what it means to query a database. The combination of a navigational model with data flows enables expressions that naturally reflect business inquiries. The HTSQL translator uses SQL as a target assembly language, which allows us to fix the query model and language while keeping current investment in relational systems.
“For each department, please show the department name and the corresponding school’s campus.”
This business inquiry clearly separates the requested rows (each department) and columns (department name and corresponding school’s campus), but this separation is lost when the query is encoded in SQL:
SELECT d.name, s.campus
FROM ad.department AS d
LEFT JOIN ad.school AS s
ON (d.school_code = s.code);
In this SQL query, the FROM clause not only picks target rows, but also includes extra tables required to produce output columns. This conflation makes it difficult to determine business entities represented by each row of the output.
The HTSQL translation separates the row definition from the column selection. The linking is implicit, and correct. The encoded query can be read aloud as a verbal inquiry.
“For each department, return the department’s name and number of courses having more than 2 credit hours.”
This business inquiry returns department records, and for each record summarizes associated courses meeting a particular criteria.
SELECT d.name, COUNT(SELECT TRUE FROM ad.course AS c
WHERE c.department_code = d.code
AND c.credits > 2)
FROM ad.department AS d;
For this SQL encoding, the WHERE clause of the subquery conflates the linking of course to department with the filter criteria.
SELECT d.name, COUNT(c)
FROM ad.department AS d
LEFT JOIN ad.course AS c
ON (c.department_code = d.code
AND c.credits > 2)
GROUP BY d.name;
In a common optimization, the correlated subquery is replaced with a GROUP BY projection. This encoding further obfuscates the business inquiry by conflating in two ways — row/column and link/filter.
The HTSQL translation keeps the filter criteria separate from linking and the row definition separate from output columns. The query adheres the form of the original business inquiry.
“How many departments by campus?”
This business inquiry asks for rows corresponding to each campus, and for each row, the number of correlated departments. In the schema, there isn’t a campus table, so we have to take distinct values of campus column from the school table. This operation is called projection.
SELECT s.campus, COUNT(d)
FROM ad.school AS s
LEFT JOIN ad.department AS d
ON (s.code = d.school_code)
WHERE s.campus IS NOT NULL
GROUP BY s.campus;
For this SQL encoding, the GROUP BY clause combines two operations: projection and evaluating the aggregate COUNT(). This conflation causes a reader of the query some effort determining what sort of rows are returned and how the aggregate is related to those rows.
In the HTSQL query, we start with an explicit projection (the ^ operator), then we select correlated columns. This way, the aggregation is indicated separately as part of the column selector rather than being conflated with the row definition.
“For each department, return the department name and the number of offered 100’s, 200’s, 300’s and 400’s courses.”
In this business inquiry, we are asked to evaluate the same statistic across multiple ranges.
SELECT d.name,
COUNT(CASE WHEN c.no BETWEEN 100 AND 199 THEN TRUE END),
COUNT(CASE WHEN c.no BETWEEN 200 AND 299 THEN TRUE END),
COUNT(CASE WHEN c.no BETWEEN 300 AND 399 THEN TRUE END),
COUNT(CASE WHEN c.no BETWEEN 400 AND 499 THEN TRUE END)
FROM ad.department AS d
LEFT JOIN ad.course AS c
ON (c.department_code = d.code)
GROUP BY d.name;
This query is tedious to write and error prone to maintain since SQL provides no way to factor the repetitive expression COUNT(...).
The HTSQL translation avoids this duplication by defining a calculated attribute count_courses($level) on the department table and then evaluating it for each course level.
“For each school with a degree program, return the school’s name, and the average number of high-credit (>3) courses its departments have.”
This business inquiry asks us to do the following:
SELECT s.name, o.avg_over_3
FROM ad.school AS s
JOIN ad.program AS p ON (p.school_code = s.code)
LEFT JOIN (
SELECT d.school_code, AVG(COALESCE(i.over_3,0)) AS avg_over_3
FROM ad.department d
LEFT JOIN (
SELECT c.department_code, COUNT(c) AS over_3
FROM ad.course AS c WHERE c.credits > 3
GROUP BY c.department_code
) AS i ON (i.department_code = d.code)
GROUP BY d.school_code
) AS o ON (o.school_code = s.code)
GROUP BY s.name, o.avg_over_3;
Not only is this SQL encoding is hard to read, it took several passes to get right — without the COALESCE you get results that look correct, but aren’t.
Each syntactic component of the HTSQL query is self-contained; when assembled, they form a cohesive translation of the business inquiry.